
假设场景:
假如你获得了一台带虹膜验证机器的部分权限,能够进入到这个机器的部分目录中,但是只有模型文件(model.h5)的读写权限,这种情况下你要怎么进行下一步呢?(当然这里的模型文件可以是其他数据,如json等,这里以HDF5格式举例)。
我的思路:
拿到模型文件后,通过修改模型的权重和偏差来实现绕过它的权限验证过程(各位靓仔你们还别不信,keras就使用模型来存储包括权重和偏差在内的所有神经网络结构数据)。
首先,虹膜扫描器这种生物扫描器的结果一定是一个分类,“通过”类或者是“拒绝”类,又或者是具体到某一个人“路人甲”类特征,“路人乙”类特征。
现在我们的目标是通过修改模型文件让机器学习程序把我们的错误特征给划到我们想要的分类去。(这里的话尽量不要去修改输入输出的数据格式或者删除模型图层数据,这会使深度学习程序报错。)最方便的方法使修改层权重和偏差数据。当前在深度学习模型中,修改中间层的权重和偏差会发生什么事情无法预测,不过在最后一层,修改其中的权重或偏差数据很容易影响深度学习的结果。

深度学习的分类器工作过程如上图所示,简化下来就如下图所示。


如果我们将最后一层的输出偏差设一个很高的值的话,那么就可以很轻易地影响最后的分类结果。
如图,假如这是一个模型的运算过程,在模型最后一层w的运算结果如果偏差如果小于1的话把它归类为“允许通过”,其他则归类为“访问拒绝”。这里我们通过修改这个偏差将其改为1000000.0,那么这个偏差参数会很大地影响深度学习结果,几乎所有的初始输入都会被错误地归类到“允许通过”类中。
通过伪造初始输入数据也可以攻击这种AI分类器,但是很明显有选择的话还是修改模型参数的攻击方式更方便些。【滑稽】。这种攻击方式不光可以在远程实现,也可以直接通过硬件接触实现。
实际演示:
这里用一个实际的深度学习分类器来演示下。
这是一个8层的深度学习模型,主要结构为Conv-- Conv -- MaxPool -- Dense –Dense。dense_2为最后一层。这个模型的作用是验证输入数据是不是4,如果是4的话就授权通过,不是的话就拒绝访问。

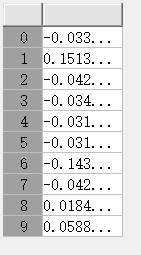
模型数据正常的时候,dense_2的原来偏差值比较小
如果我们给一个数字2,在修改前模型正常的运行结果是AccessDenied,因为它不是4。
当我们修改dense_2层中的一个偏差值并将其设置为一个比较大的值后(这里将value4改成了1000.0),再次运行,深度学习模型的运行结果是AccessGranted。通过修改深度学习模型的偏差值,我们成功地改变了它的运行结果。

蓝队方案:
有些程序员没有把模型文件看作和程序文件一样的敏感文件,而随随便便把它放在一个不安全的地方。
在安全角度,我们要将模型文件当作敏感文件,对其应该加以防护(限制访问,添加密码等),不能给这些读或写的权限,可以的话应该对它进行加密。即使这个模型并不涉及安全相关的应用,这些内容也可能含有组织的相关信息,起码要保护下撒。
碎碎念:修改模型进行攻击不一定要限定在攻入带验证机器场景中,机器也不一定是带验证的高档机器,哪怕仅仅是一个门禁什么的,我修改了模型之后也会有安全隐患。
深度学习基础可见:从1到无穷大--深度学习篇

